In a world of interconnected devices, data is being generated at an unprecedented rate. To take advantage of this data, engineers often employ Machine Learning (ML) techniques that allow them to gather valuable insights and actionable information. As the volume of data increases, there is the need to run big data processing pipelines at scale – your laptop just won’t cut it.
To help remedy this, we can use distributed frameworks such as Spark, that allow us to use distributed computing to analyze our data. In this two-part series, you’ll take a small step towards running your data workloads at scale. We present a hands-on tutorial where you’ll learn how to use AWS services to run your processing on the cloud. To do this, we’ll launch an EMR cluster using Lambda functions and run a sample PySpark script. You will need an AWS account to follow this series, as we’ll be using their services.
In this first part, we’ll take a high-level peek at the technologies and architecture, and take a look at a sample problem. In part 2, we’ll dive into the details including architecture and set up of necessary infrastructure.
Before diving into our sample problem, let’s briefly review the architecture and AWS services involved. We’ll be using Spark, an open-source distributed computing framework for processing large data volumes. Spark can be run on EMR, and we’ll be using its Python API, PySpark. AWS Elastic MapReduce (EMR) is a managed service that simplifies the deployment and management of Hadoop and Spark clusters. Simple Storage Service (S3) is Amazon’s object storage service, which we’ll use to store our PySpark script.
To create the EMR cluster, we’ll use AWS Lambda, a serverless compute service which allows us to run code without the need to provision or manage servers. Using Lambda to create the cluster allows us to define infrastructure as code, so we can define the cluster specifications and configurations once and execute multiple times. We can then launch multiple clusters easily using the same function. Lambda also enables us to define automatic triggers, which we can use to provision clusters automatically based on a set of actions.
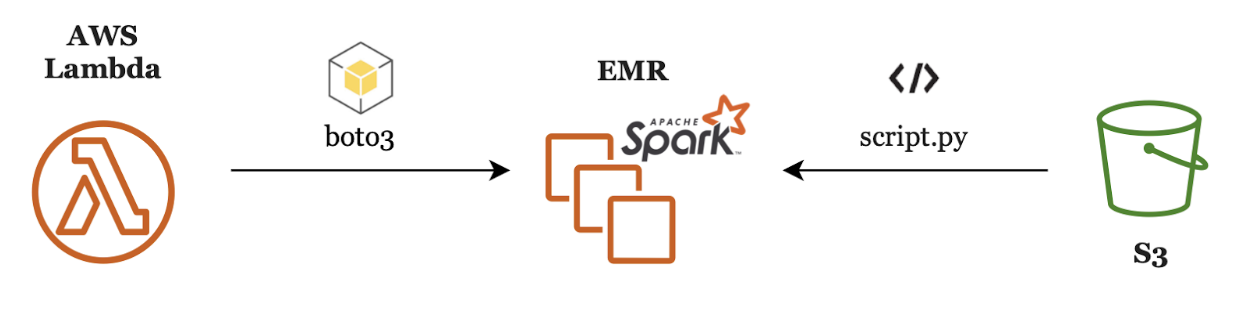
In our sample use case, we’ll create a Python script using AWS’s Python library boto3. This script will be loaded on AWS Lambda and it will trigger the EMR cluster to run our sample PySpark script. The latter will be stored in S3, from where the EMR cluster will retrieve it at runtime.
We have created a very simple Python script to train a machine learning model using Spark. We’ll generate random data, calculate a linear combination of it, add noise to the results and train a model so that the model can learn how we combined the data. The model should be able to filter out the noise and pretty accurately figure out the coefficients we used to calculate the linear combination of the input data.
In this section we’ll walk you through the code, explaining code blocks and commenting on the used functions. At the end you will have the full script available.
We’ll be using arguments for our script so we need to import argparse. We’re importing SparkSession to get a hold of the running Spark session. We’ll be using user-defined functions so we need pyspark.sql.types and pyspark.sql.functions. In this example we’ll fit a linear regression model from Spark’s MLlib. The features this model needs are formatted using VectorAssembler. Finally, the model will be evaluated with the built in RegressionMetrics.
Next, define the number of rows of synthetic data we’ll generate. On lines 14-22 we set up the arguments parser so we can pass parameters to the script. This is a great feature we can use at our advantage when performing tests, and increases the modularity of our code. We’re telling the parser the names of our arguments, if they are required to run the program and their data type. Note the arguments are passed as strings on the Lambda function, and the parser casts them to the specified type.
In line 25-28 we're obtaining the Spark Session.
Between lines 31 and 32, we’re initializing a new dataframe with numbers ranging from zero to NUM_SAMPLES – 1. Although this is not directly required, it is an easy way of initializing the dataframe for our purpose. Due to how we’re generating the dataframe, it has a single partition. If that’s the case, all the processing will be done by one machine belonging to the cluster. We’re repartitioning the dataframe into four partitions, this way, the processing will be distributed across the cluster. Note this is correct for our current example, but performing this operation on large amounts of data can result in an expensive shuffle.
On lines 35-36 we’re generating two columns with random values using Spark’s rand function. This generates uniformly distributed random numbers in the range [0,1). We’ll use these as features for our model
On lines 43-46 we’re calculating a linear combination of the two generated columns, using the multipliers passed by arguments. We’re then generating another column with random samples called noise on line 49. As the noise is generated in the range [0,1), we’re subtracting 0.5 to shift the range to [-0.5,0.5). This noise is then added to the linear combination we created on lines 56-58. The purpose of it is to add noise to the data, because if the data was perfect, only a couple of samples would be needed to calculate the coefficients.
On line 64, we instantiate a LinearRegression model from Spark’s MLlib to be fit. As the model is fitted with an input dataframe, we’re telling it which columns to search for when given a dataframe, in our case features (inputs) and label (target output).
MLlib’s models require the data input to be formatted in a specific way, and the VectorAssembler helps us achieve just that. We’re going from two separate columns containing float values to one DenseVector which contains both float features. In line 68 we’re instantiating the VectorAssembler and in line 70 we’re actually using it to transform our data.
As standard practice on ML problems, we’re splitting the data into training and testing. The training data is used to fit the model. The test data is used to evaluate the model on unseen data once it is fitted. It’s kind of simulating what would happen in production. We’re using Spark’s randomSplit to do this, and we’re telling it we want 80% of the data for training and 20% for testing.
This is where the magic happens! In line 77 we’re fitting the model. In the following lines, some info and metrics of the training process are printed to stdout. Note we’re also printing the coefficients learned by the model. If things go well, these should be extremely close to those coefficients which were passed by arguments. They should be close and not exactly equal due to the noise we have introduced to the data.
Remember the test data? This is where we use it to evaluate the performance of the model on unknown data. We’re transforming the test dataframe with the already fitted model, which will generate a new column called prediction with the output. Using Spark’s built in RegressionMetrics, we get two metrics for the results on the test data. These are the same metrics as those we got from the training summary, so you can compare the performance of the model on training vs. test data.
Let’s take a glance at the script’s output. The first dataframe being displayed is the result of line 38, and contains the randomly generated inputs. The second one is the result of line’s 61 execution, where we’re displaying the randomly generated values, the linear combination of those, randomly generated noise and the addition of the linear combination and the noise. Training information is then printed, including the number of iterations of the linear regression algorithm, metrics such as RMSE and r2, and the calculated model coefficients. These should be very close to the ones we’re using as inputs x1 and x2. Finally, a portion of the test dataframe is shown, including the inputs (features), the label and the model’s prediction. Metrics on the test data should closely resemble the ones for training.
In this first part of the series, we reviewed the high level architecture we’ll be using to run distributed data processing on AWS. For illustration purposes, we set up an extremely simple example script using pySpark, the Spark API for Python. We reviewed the script and what it does.
In part 2, we’ll dive into the details of running this script on EMR. We’ll explain the technologies to be used and set up the necessary infrastructure to run the example.
In a world of interconnected devices, data is being generated at an unprecedented rate. To take advantage of this data, engineers often employ Machine Learning (ML) techniques that allow them to gather valuable insights and actionable information. As the volume of data increases, there is the need to run big data processing pipelines at scale – your laptop just won’t cut it.
To help remedy this, we can use distributed frameworks such as Spark, that allow us to use distributed computing to analyze our data. In this two-part series, you’ll take a small step towards running your data workloads at scale. We present a hands-on tutorial where you’ll learn how to use AWS services to run your processing on the cloud. To do this, we’ll launch an EMR cluster using Lambda functions and run a sample PySpark script. You will need an AWS account to follow this series, as we’ll be using their services.
In this first part, we’ll take a high-level peek at the technologies and architecture, and take a look at a sample problem. In part 2, we’ll dive into the details including architecture and set up of necessary infrastructure.
Before diving into our sample problem, let’s briefly review the architecture and AWS services involved. We’ll be using Spark, an open-source distributed computing framework for processing large data volumes. Spark can be run on EMR, and we’ll be using its Python API, PySpark. AWS Elastic MapReduce (EMR) is a managed service that simplifies the deployment and management of Hadoop and Spark clusters. Simple Storage Service (S3) is Amazon’s object storage service, which we’ll use to store our PySpark script.
To create the EMR cluster, we’ll use AWS Lambda, a serverless compute service which allows us to run code without the need to provision or manage servers. Using Lambda to create the cluster allows us to define infrastructure as code, so we can define the cluster specifications and configurations once and execute multiple times. We can then launch multiple clusters easily using the same function. Lambda also enables us to define automatic triggers, which we can use to provision clusters automatically based on a set of actions.
In our sample use case, we’ll create a Python script using AWS’s Python library boto3. This script will be loaded on AWS Lambda and it will trigger the EMR cluster to run our sample PySpark script. The latter will be stored in S3, from where the EMR cluster will retrieve it at runtime.
We have created a very simple Python script to train a machine learning model using Spark. We’ll generate random data, calculate a linear combination of it, add noise to the results and train a model so that the model can learn how we combined the data. The model should be able to filter out the noise and pretty accurately figure out the coefficients we used to calculate the linear combination of the input data.
In this section we’ll walk you through the code, explaining code blocks and commenting on the used functions. At the end you will have the full script available.
We’ll be using arguments for our script so we need to import argparse. We’re importing SparkSession to get a hold of the running Spark session. We’ll be using user-defined functions so we need pyspark.sql.types and pyspark.sql.functions. In this example we’ll fit a linear regression model from Spark’s MLlib. The features this model needs are formatted using VectorAssembler. Finally, the model will be evaluated with the built in RegressionMetrics.
Next, define the number of rows of synthetic data we’ll generate. On lines 14-22 we set up the arguments parser so we can pass parameters to the script. This is a great feature we can use at our advantage when performing tests, and increases the modularity of our code. We’re telling the parser the names of our arguments, if they are required to run the program and their data type. Note the arguments are passed as strings on the Lambda function, and the parser casts them to the specified type.
In line 25-28 we're obtaining the Spark Session.
Between lines 31 and 32, we’re initializing a new dataframe with numbers ranging from zero to NUM_SAMPLES – 1. Although this is not directly required, it is an easy way of initializing the dataframe for our purpose. Due to how we’re generating the dataframe, it has a single partition. If that’s the case, all the processing will be done by one machine belonging to the cluster. We’re repartitioning the dataframe into four partitions, this way, the processing will be distributed across the cluster. Note this is correct for our current example, but performing this operation on large amounts of data can result in an expensive shuffle.
On lines 35-36 we’re generating two columns with random values using Spark’s rand function. This generates uniformly distributed random numbers in the range [0,1). We’ll use these as features for our model
On lines 43-46 we’re calculating a linear combination of the two generated columns, using the multipliers passed by arguments. We’re then generating another column with random samples called noise on line 49. As the noise is generated in the range [0,1), we’re subtracting 0.5 to shift the range to [-0.5,0.5). This noise is then added to the linear combination we created on lines 56-58. The purpose of it is to add noise to the data, because if the data was perfect, only a couple of samples would be needed to calculate the coefficients.
On line 64, we instantiate a LinearRegression model from Spark’s MLlib to be fit. As the model is fitted with an input dataframe, we’re telling it which columns to search for when given a dataframe, in our case features (inputs) and label (target output).
MLlib’s models require the data input to be formatted in a specific way, and the VectorAssembler helps us achieve just that. We’re going from two separate columns containing float values to one DenseVector which contains both float features. In line 68 we’re instantiating the VectorAssembler and in line 70 we’re actually using it to transform our data.
As standard practice on ML problems, we’re splitting the data into training and testing. The training data is used to fit the model. The test data is used to evaluate the model on unseen data once it is fitted. It’s kind of simulating what would happen in production. We’re using Spark’s randomSplit to do this, and we’re telling it we want 80% of the data for training and 20% for testing.
This is where the magic happens! In line 77 we’re fitting the model. In the following lines, some info and metrics of the training process are printed to stdout. Note we’re also printing the coefficients learned by the model. If things go well, these should be extremely close to those coefficients which were passed by arguments. They should be close and not exactly equal due to the noise we have introduced to the data.
Remember the test data? This is where we use it to evaluate the performance of the model on unknown data. We’re transforming the test dataframe with the already fitted model, which will generate a new column called prediction with the output. Using Spark’s built in RegressionMetrics, we get two metrics for the results on the test data. These are the same metrics as those we got from the training summary, so you can compare the performance of the model on training vs. test data.
Let’s take a glance at the script’s output. The first dataframe being displayed is the result of line 38, and contains the randomly generated inputs. The second one is the result of line’s 61 execution, where we’re displaying the randomly generated values, the linear combination of those, randomly generated noise and the addition of the linear combination and the noise. Training information is then printed, including the number of iterations of the linear regression algorithm, metrics such as RMSE and r2, and the calculated model coefficients. These should be very close to the ones we’re using as inputs x1 and x2. Finally, a portion of the test dataframe is shown, including the inputs (features), the label and the model’s prediction. Metrics on the test data should closely resemble the ones for training.
In this first part of the series, we reviewed the high level architecture we’ll be using to run distributed data processing on AWS. For illustration purposes, we set up an extremely simple example script using pySpark, the Spark API for Python. We reviewed the script and what it does.
In part 2, we’ll dive into the details of running this script on EMR. We’ll explain the technologies to be used and set up the necessary infrastructure to run the example.
Lorem ipsum dolor sit amet consectetur. Sit sit vel eu sed proin. Arcu bibendum in mauris urna erat magna volutpat eget. Lectus commodo consectetur egestas quis ut lobortis nunc.
.png)
Lorem ipsum dolor sit amet consectetur. Sit sit vel eu sed proin. Arcu bibendum in mauris urna erat magna volutpat eget. Lectus commodo consectetur egestas quis ut lobortis nunc.









.jpeg)